


Tentando uma definição abrangente de Data Science
Buscamos o que se tem teorizado e discutido sobre o que é Data Science. Há muito por aí. Veremos o estágio atual, comparações com a Estatística, interdisciplinaridade e como a tarefa não é tão simples


Uma tarefa interessante no aprendizado de Data Science (ou mesmo a quem já atua na área, para refrescar a memória), que costuma aparecer em aulas introdutórias de cursos como o da Awari, é tentar definir a área em nossas próprias palavras.
Vale consultar outras fontes, é claro. Mas tente construir um resumo com o que você conseguir intuir de suas pesquisas e do seu próprio processo de pensamento.
Provavelmente, você começará a notar que o campo é bem mais abrangente do que se consegue colocar em uma ou duas linhas. Talvez descobrirá que ele pode ir muito além do que você imagina em um primeiro momento.
Pode até parecer que Data Science se releve como uma dessas áreas “universais”, que se aplica a tudo, a todos os aspectos dos negócios, do trabalho, das ciências e até da vida — e é por aí mesmo.
Talvez você queira se aprofundar e entender mais de onde a área surge, como se desenvolve e quais suas tendências para os próximos dois, três, cinco ou dez anos.
O melhor é que isso pode ser feito aos poucos, enquanto coloca a mão na massa em código, estatísticas e modelos. Talvez se torne um processo rodando em background: nos pegaremos, vez ou outra, revisando a definição da área, sua evolução e seus rumos a partir de novas evidências.
Este artigo é uma tentativa de ajudar com esse processo de descoberta, mais do que apenas de definição, do que é Ciência de Dados e qual sua abrangência.
A ideia é irmos um pouco além dos resumos de três linhas e nos apoiarmos em quem já pesquisou e pensou a sério no que consiste a área.
Definições cabais são impossíveis, até porque o campo é relativamente novo e está em evolução rápida. Com seu amadurecimento, talvez se chegue a um denominador comum. Mas podemos arriscar alguma exploração e expansão a partir do que outros já tem pensado a respeito.
Uma área definida na prática
É interessante notar que muitas áreas do conhecimento, sobretudo do conhecimento mais teórico e científico (da epistemologia, em sentido amplo), foram definidas mais por estudiosos, por meio de pensamento rigoroso, do que por prática. A prática contribuiu, é claro, mas em geral derivou da teoria e não a precedeu.
A princípio, por lidar com estatística, matemática, computação e ter sido associada a áreas acadêmicas e graus de PhD ao longo de sua recente existência, a Ciência de Dados poderia parecer apenas mais um caso dessa linhagem. Algo a ser primeiro definido e estruturado teoricamente, para depois ser aplicado.
Não tem sido assim. Data Science é um campo amplo e cross-domain (perpassa diversos domínios), que vem sendo definido dia após dia pela prática de batalhões de pessoas em várias partes do mundo, na academia, em empresas e startups, no governo, em laboratórios, na indústria ou mesmo por meio de iniciativas e projetos pessoais.
As contribuições vêm desde PhDs nível NASA ou, quem sabe, até prêmios nobéis de Economia, passando por estatísticos e matemáticos de carreira, analistas financeiros, econometristas, engenheiros de todos os tipos, biólogos, epidemiólogos, sociólogos, marqueteiros e um exército de aspirantes, recém-iniciados, formados em sistemas de informação, ciência da computação ou apenas em bootcamps e cursos de Ciência de Dados, quando não autodidatas puros.
Isso faz da Ciência de Dados diversa, plural e interdisciplinar por excelência. Não há definições que consigam abranger, devidamente, todas essas nuances, contribuições e faces do campo.
Além disso, como a área é nova, recente e está em evolução rápida — é dinâmica — tentativas de definição com alto poder de síntese são prejudicadas.
Em pouco tempo, novas práticas, domínios, ferramentas (principalmente estas) e conhecimentos são adicionados, o que torna obsoletas consolidações anteriores.
(Quase tudo o que é relacionado à tecnologia da informação, na verdade, passa por esse dinamismo; se isso é problema ou oportunidade, depende de como se observa).
É por conta dessas circunstâncias que definições de Data Science sempre parecem incompletas (basta fazer o exercício proposto lá no início), quando não equivocadas (dependendo, de novo, de como se observa).
No senso comum, veremos tentativas de definições rápidas (e rasas, não teria como ser diferente) como: “Ciência de Dados é uma área que junta estatística, computação e machine learning para descobrir insights de dados”. Ou, um pouco menos definidor: “Ciência de Dados é uma área que lida com campos como big data e Inteligência Artificial (IA)”.
A Wikipédia (em inglês, em que tópicos de tecnologia tendem a ser melhores) talvez ajude um pouco mais:
“Ciência de Dados é um campo interdisciplinar que usa métodos científicos, processos, algoritmos e sistemas para extrair conhecimento e insights de dados ruidosos, estruturados e não estruturados, e aplicar conhecimentos e insights acionáveis em uma ampla gama de domínios de aplicação. A ciência de dados está relacionada a data mining [mineração de dados], machine learning e big data.” — Wikipedia.
Podemos entrar em debates sem fim sobre se deveríamos incluir Deep Learning como subcampo de Data Science, se Estatísticas e Probabilidades deveriam ser mencionadas explicitamente em quaisquer descrições, se Matemática está implícita na Estatística ou não (alguns observarão que otimização é Matemática, mas não Estatística).
Será que descrições mais informais, com alguma “sacada”, ajudam a dar uma noção mais assertiva?
No artigo “Muito além da profissão mais sexy do século”, comentamos sobre o artigo de Thomas Davenport e DJ Patil que vendeu Data Science como “o trabalho mais sexy do século”.
Nele, os autores definem o cientista de dados (o que pode servir para definir a Ciência de Dados também), como:
“Pense nele [cientista de dados] como um híbrido de hacker de dados, analista, comunicador e consultor confiável. A combinação é extremamente poderosa — e rara.” — Davenport e Patil.
De “Uma abordagem conceitual sobre Modelos”, podemos tomar emprestada outra definição, de Sanjiv Ranjan Das, que observa Data Science como uma área que nasceu e tem se desenvolvido principalmente para entender consumidores no âmbito de marketing, vendas, em resumo, negócios:
“A ciência de dados trata da quantização e compreensão do comportamento humano, o Santo Graal das ciências sociais.” — Sanjiv Ranjan Das.
O senso comum e pitacos ajudam a somar percepções. Mesmo assim, pode parecer que que falta algo mais robusto, com algum processo de pensamento mais teórico por trás, para definições melhores. Vamos ver o que encontramos.
Teorizações e reivindicações da Estatística
Ciência de Dados é um campo que deriva, em grande parte, tanto da Estatística quanto da Ciência da Computação. Atualmente, com todo o enfoque em infraestrutura e engenharia de dados, produtização de dados e machine learning, a impressão que se tem é que ela se adequaria melhor como um braço da Computação do que da Estatística.
Mesmo assim, foi a partir da Estatística que o termo “Data Science” começou a ser formulado, com várias tentativas de definições durante décadas.
Não Data Science, propriamente, mas Data Analysis, que é um termo que se relaciona e às vezes se confunde com a Ciência de Dados (mais um ingrediente na sopa da confusão), é uma terminologia definida por John Tukey em 1977.
Tukey é um precursor da Ciência de Dados, de qualquer forma, porque é responsável por tirar a Estatística de uma busca puramente matemática e teórica e situá-la como um campo prático.
É dele o conceito de Exploratory Data Analysis (EDA) ou Análise Exploratória de Dados, uma etapa fundamental do processo de Ciência de Dados.
Por falar em processo, o Knowledge Discovery in Databases (KDD), de 1989, uma rotina de etapas clássica para ciência de dados, e Data Mining (mineração de dados), ora tida como um campo próprio, ora uma etapa do KDD, também são precursores da Ciência de Dados.
Muito do que se pensou e se tentou elaborar sobre o conceito de Data Science, ao longo do tempo, deriva do que se fazia em EDA, Data Mining e nos frameworks de gerenciamento de projetos de análise de dados como KDD, CRISP-DM e SEMMA.
Assim, alguns nomes importantes dessas áreas, que lidavam com computação, mas eram basicamente estatísticos, lançaram bases do que se enriqueceria depois como Ciência de Dados.
Em 1997, em “Statistics = Data Science”, Jeff Wu perguntou se a Estatística não deveria ser renomeada para Ciência de Dados. A intenção, de qualquer forma, era ajudar a evoluir a Estatística para a era de Big Data que já se prenunciava.
Em 2001, Willian S. Cleveland sugeria que as Estatísticas passassem a ampliar sua área de trabalho em parceria com cientistas da computação, um “híbrido”.
Também em 2001, Leo Breiman sugeria que a Estatística deveria sair da dependência exclusiva de modelos de dados (data models) e ir para uma abordagem de modelagem algorítmica (algorithmic modeling).
(Esses nomes citados acima e a história de Data Science a partir da Estatística está para lá de consolidada no artigo “50 Years of Data Science”, de David Donoho, que já apareceu algumas vezes em textos anteriores nossos).
Então, Ciência de Dados ainda era sobre Estatística ou já estava se tornando muito mais Computação?
Por que, afinal, a Estatística passou a reivindicar para si, como um nome “reservado”, como diz Wu, a denominação de Ciência de Dados, tentando defini-la várias vezes?
Aqui, vale observar a história mais ampla. A Computação, em especial a computação digital, é um campo crescente desde, mais ou menos, a década de 1950 (daqui a pouco já vai fazer quase um século!).
Ela não tinha nada a perder, só a ganhar, com métodos e rotinas como mineração de dados, descoberta de conhecimento em bancos de dados e toda essa parte, digamos, “computacional-analítica”.
Por outro lado, a Estatística tinha muito a perder com os avanços de big data que se prenunciavam, com computadores automatizando pesquisas e análises e com algoritmos avançando sobre campos preditivos, que eram muito mais atraentes e avançados do que os apenas descritivos e inferenciais em que estatístico então ela atuavam.
A Estatística tinha, então, de tomar a frente do processo de alguma maneira. Trazia contribuições necessárias e significativas, sim, mas precisava acompanhar o bonde de história para não se ver ofuscada.
É por conta disso, em grande parte, tamanha associação de Data Science à Estatística até hoje, como se fosse um braço ou ramo dela ou uma continuidade sua — embora, atualmente, talvez já seja adequado considerar a Estatística apenas parte da Ciência de Dados.
A Estatística continua tentando ter sua parte de contribuição no desenvolvimento da Ciência de Dados, como é natural. Hoje, porém, já usa definições mais amplas, como por exemplo:
“A ciência de dados como disciplina científica é influenciada pela informática, ciência da computação, matemática, pesquisa operacional e estatística, bem como pelas ciências aplicadas.” — Claus Weihs e Katja Ickstadt, em “Data Science: the impact of statistics”.
O artigo em questão, por acaso, tenta uma definição processual de Ciência de Dados mais atualizada, como a seguinte sequência de etapas:
Aquisição e enriquecimento de dados;
Armazenamento e acesso aos dados;
Exploração de dados;
Análise e modelagem de dados;
Otimização de algoritmos;
Seleção e validação do modelo;
Representação e comunicação dos resultados
Deploy dos resultados.
Comparado com o CRISP-DM, por exemplo, em que o estudo se baseia e que tem menos etapas (entendimento de negócio, entendimento dos dados, preparação dos dados, modelagem, avaliação e deploy), a proposta demonstra como a própria evolução prática da Ciência de Dados obrigou a teoria a se atualizar.
Otimização de algoritmos é, nitidamente, um incremento que o Machine Learning impôs às etapas, o que ajuda a pensar na abrangência da Ciência de Dados.
Não é só Estatística. Não é só Computação. Não se consegue resumir tudo como Machine Learning. É tudo isso e mais.
Aprofundando
A abordagem mais completa sobre todas as nuances de Data Science parece ser “Data Science: A Comprehensive Overview”, de 2016 — ou seja, já pode precisar de atualizações — de Longbing Cao, da Universidade de Tecnologia de Sydney, na Austrália (finalmente, um não americano entre as referências).
O artigo é longo, muito detalhado e referenciado. Vamos destacar algumas partes que podem ajudar com uma definição mais compreensiva de Data Science. Para uma noção mais completa de todo o tratamento do autor, vale uma conferida no original (em inglês).
Cao revela, por exemplo, que o primeiro aparecimento de “ciência de dados” data de 1974, no prefácio de um livro chamado Concise Survey of Computer Methods, de Peter Naur — na computação, portanto. A definição da época era:
“[...] ciência de lidar com dados, uma vez eles foram estabelecidos, enquanto a relação dos dados com o que eles representam é delegado a outros campos e ciências.” — Peter Naur, citado por Longbing Cao.
Antes, em 1968, já se tinha usado o termo “datalogia” para designar algo parecido: “a ciência dos dados e dos processos de dados”. A história prossegue com Tukey e as demais referências.
Cao também relaciona uma série de outras nomenclaturas que são associadas e costumam se confundir com Data Science. Alguns termos são populares (data analytics, por exemplo), outros são menos conhecidos e usados por ele ao longo do artigo.
Advanced analytics: refere-se a teorias, tecnologias, ferramentas e processos que permitem uma compreensão aprofundada e descoberta de insights acionáveis em big data, que não pode ser alcançado pela análise e processamento de dados tradicionais teorias, tecnologias, ferramentas e processos.
Big data: refere-se a dados que são muito grandes e/ou complexos para serem tratadas com eficiência e/ou eficácia por teorias, tecnologias e ferramentas tradicionais.
Data analysis: refere-se ao processamento de dados tradicional (por exemplo, estatística clássica, teorias matemáticas ou lógicas, tecnologias e ferramentas para obter informações úteis e para fins práticos).
Data analytics: refere-se às teorias, tecnologias, ferramentas e processos que permitem uma compreensão aprofundada e descoberta de uma visão prática dos dados. Consiste em análises descritivas, análises preditivas e análises prescritivas.
Data Science: “é a ciência dos dados” (o artigo, afinal, é a explicação).
Análise descritiva: refere-se ao tipo de análise de dados que normalmente usa estatísticas para descrever os dados usados para obter informações ou para outros fins úteis.
Análise preditiva: refere-se ao tipo de análise de dados que faz previsões sobre eventos futuros desconhecidos e divulga as razões por trás deles, normalmente por análises avançadas.
Análise prescritiva: refere-se ao tipo de análise de dados que otimiza as indicações e recomenda ações para uma tomada de decisão inteligente.
Análise explícita: concentra-se em análises descritivas, normalmente por meio de relatórios descritivos, alertas e previsão.
Análise implícita: concentra-se em análises profundas, normalmente por modelagem preditiva, otimização, análises prescritivas e entrega de conhecimento acionável.
Análise profunda: refere-se a análises de dados que podem adquirir uma compreensão aprofundada de por que e como as coisas aconteceram, estão acontecendo ou irão acontecer, o que não pode ser abordado por análises descritivas.
Na parte “O que é Data Science”, Cao cita Wu, Cleveland, Breiman e contextualiza algumas percepções importantes sobre a interdisciplinaridade da área e a multiplicidade de interpretações sobre o termo:
“A arte da ciência de dados atraiu um interesse crescente de uma ampla gama de domínios e disciplinas. Assim, comunidades ou proponentes de diversos fundos, com aspirações contrastantes, apresentam visões ou focos muito diferentes. Alguns exemplos são que a ciência de dados é a nova geração de estatísticas, é uma consolidação de vários campos interdisciplinares ou é um novo corpo de conhecimento. Ciência de dados também tem implicações no fornecimento de recursos e práticas para a profissão de dados, ou para geração de estratégias de negócios.” — Longbing Cao.
E emenda, acrescentando alguns termos novos que também temos de lembrar no contexto da Ciência de Dados atual, como gestão e tomada de decisão:
“Discussões intensivas ocorreram dentro da comunidade acadêmica e de pesquisa sobre a criação de ciência de dados como uma disciplina acadêmica. Isso não envolve apenas estatísticas, mas também um corpo de conhecimento multidisciplinar que inclui a computação, comunicação, gestão e decisão. O conceito de ciência de dados é correspondentemente definido a partir da perspectiva do desenvolvimento disciplinar e do curso: por exemplo, tratando ciência de dados como uma mistura de estatística, matemática, ciência da computação, design gráfico, mineração de dados, interação homem-computador e visualização de informações” — Longbing Cao.
Na sequência, ele dá três definições de Data Science que são pérolas, além de assertivas:
em alto nível, “data science é a ciência dos dados” ou “o estudo de dados” (talvez seja a melhor resposta, se nos pedirem uma resposta rápida, de uma linha);
como disciplina, é “um novo campo interdisciplinar que sintetiza e se baseia em estatísticas, informática, computação, comunicação, gestão e sociologia para estudar dados e seus ambientes (incluindo domínios e outros aspectos contextuais, como organizacionais e aspectos sociais), a fim de transformar dados em percepções e decisões, seguindo um raciocínio e metodologia “dados-conhecimento-sabedoria”, que ele transforma em fórmula — uma maneira realmente sucinta de definir coisas —: data = statistics + informatics + computing + communication + sociology + management | data + envinroment + thinking.
como produtos de dados (data products), “um entregável de dados, ou ativado ou orientado por dados, que pode ser uma descoberta, previsão, serviço, recomendação, insight de tomada de decisão, pensamento, modelo, modo, paradigma, ferramenta ou sistema — o que, por acaso, complementa uma de nossas abordagens anteriores.
Mais insumos para se pensar no que é Data Science: quantificação. Ele lista quantificação do tempo, de lugares, de corpos, de formas, de meios, de velocidade.
Mais adiante, explica melhor a questão das análises explícitas e implícitas:
“[...] A era da análise explícita: que se concentra na análise descritiva. Abordagens analíticas típicas consistem em relatórios, análises estatísticas, alertas e previsão.
“[...] A era das análises implícitas: que se concentra em análises profundas. Abordagens analíticas típicas são modelagem preditiva, otimização, analítica prescritiva e entrega de conhecimento acionável.”
— Longbing Cao.
Por análise explícita, podemos pensar, segundo ele, no que “sabemos que sabemos” (conhecidos-conhecidos), atuamos na abordagem clássica por hipóteses e testes de hipóteses, com resultados disponíveis em matemática e estatística, auxiliados por computação, que apresentam “o que aconteceu, o que está acontecendo ou acontecerá em dados geralmente pequenos”.
Por análise implícita, devemos entender que “não sabemos o que não sabemos” (desconhecidos-desconhecidos), atuamos em abordagens de descoberta, por meio de aprendizado sobre os próprios dados, em que o resultado está em “obter um entendimento profundo, intrínseco e completo de insights, conhecimento e sabedoria invisíveis a partir de dados, comportamentos e ambientes, sobre o que aconteceu, está acontecendo ou acontecerá nos dados e negócios”.
Um gráfico do autor talvez ajude em uma compreensão mais intuitiva de quais práticas, etapas ou métodos da Ciência de Dados seriam mais “explícitos” ou mais “implícitos”:
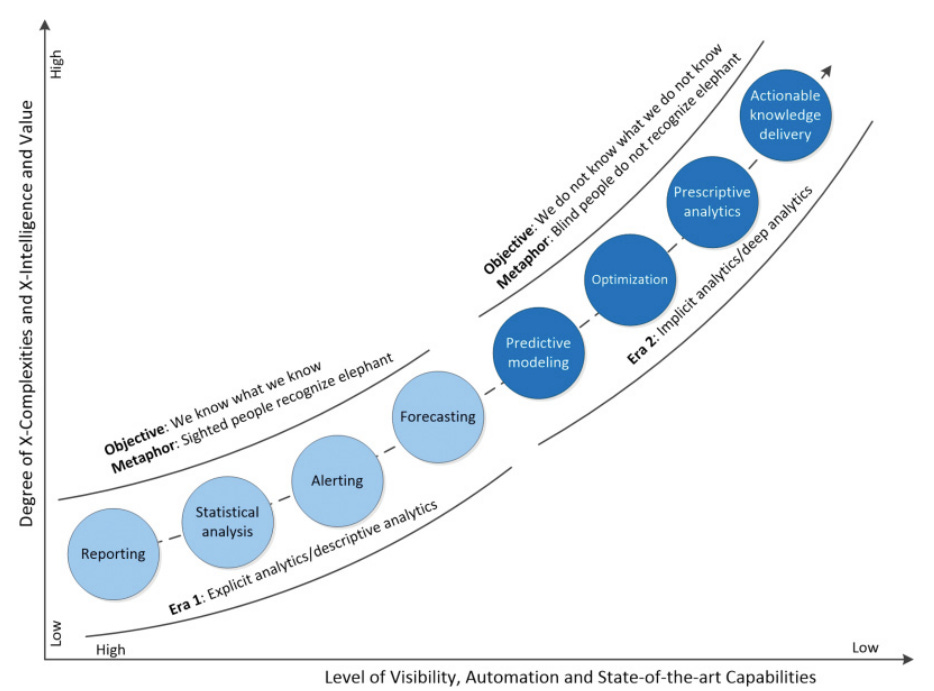
Gráfico mostra como a Ciência de Dados tende a ir de métodos mais básicos e ferramentais (mais explícitos) para a automação (mais implícita). Fonte: Longbing Cao.
Imagem mostra um gráfico que tem o que o autor chama de visibilidade de métodos no eixo X e graus de complexidade e inteligência no eixo Y. No nível maior de visibilidade e menor de complexidade, estão práticas “explícitas”, como relatórios, análise estatística e séries temporais. No nível mais implícito e de maior complexidade, estão métodos como predição, otimização, prescrição e conhecimento acionável.
Com outro gráfico, ele praticamente resume o que Data Science foi, está sendo e será de maneira ampla. A analogia também é possível com o momento e a evolução de muitas empresas e startups:
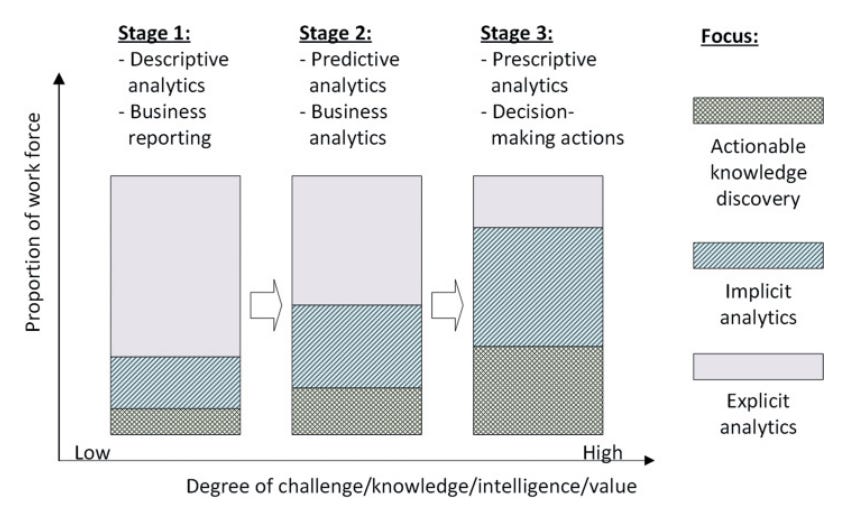
Gráfico ilustra como a migração de análises descritivas para análises prescritivas implica aumento de trabalho em análises implícitas e conhecimento acionável (mais complexos). Fonte: Longbing Cao.
Imagem mostra um gráfico que tem graus de desafios/conhecimentos no eixo X e proporções de tarefas (análises explícitas, implícitas e conhecimento acionável) no eixo Y. Há três estágios. No primeiro, análises explícitas, como relatórios de negócios, têm a maior proporção. No segundo, análises implícitas aumentam. No terceiro, tanto análises implícitas como conhecimento acionável têm a maior proporção. O gráfico representa tanto a evolução da própria Ciência de Dados como os momentos dela em muitas empresas e startups.
O Estágio 1 descreve o momento em que o trabalho se concentra em estatísticas descritivas e relatórios de negócios. Não muito mais que o Business Intelligence (BI) tradicional. O conhecimento acionável é baixo. Há pouca análise implícita e muita explícita.
O Estágio 2 é o momento em que as tarefas se concentram em análises preditivas e de negócios. Há um crescimento das análises implícitas.
O Estágio 3, por fim, é quando se avança para análises prescritivas (ações automatizadas) e tomada de decisão. Tanto análises implícitas e descoberta de conhecimento acionável crescem em proporção.
Não corresponde ao que vemos em muitos negócios e ao longo do desenvolvimento de Data Science?
Não é nessa descoberta de conhecimento acionável, em insights de negócios (a “ponta do iceberg” de dados, que tem escondida toda a infraestrutura, engenharia e ciência de dados), que queremos de fato chegar?
Isso certamente molda nossa compreensão e, consequentemente, a compreensão de Ciência de Dados no tempo.
Talvez daqui a um tempo (em breve?) Data Science já estará ofuscada, dissolvida nos motores da automação, enquanto o que brilhará serão seus resultados, os insights valiosos e as decisões automatizadas.
Cao vai muito além nas ideias que lança sobre Data Science no presente e no futuro. Ele fala de áreas de negócios e indústrias que serão impactadas, fala da educação em Ciência de Dados e cria listas e mais listas de itens que descrevem, por exemplo, o que chama de “serviços de dados”.
Apenas para dar mais alguns subsídios para pensarmos em uma definição para a Ciência de Dados, vamos ficar com duas listas (extensas, por sinal), em que ele elenca o que tem resumido a área e o que tem se buscado em bons cientistas de dados.
Nos resumos da área, temos (resumimos em outras palavras o que o autor detalha no artigo):
Domínio do problema de negócio.
Identificar e especificar questões sociais e éticas, como privacidade e segurança de dados.
Compreensão das características e complexidades dos dados, identificar seus problemas e limitações.
Configuração de processos analíticos e de engenharia para transformar dados em informações e as informações em tomadas de decisão de negócio.
Transformar problemas de negócios em tarefas analíticas, por meio de técnicas, modelos, métodos, algoritmos, ferramentas, sistemas, design experimental etc.
Extrair, analisar, construir e selecionar recursos, otimizar e inovar novas variáveis para melhor representação e modelagem de problemas.
Combinar habilidades analíticas, estatísticas, algorítmicas, de engenharia e técnicas para extrair dados relevantes envolvendo informações contextuais.
Manter, gerenciar e refinar projetos e marcos e seus processos.
Desenvolver serviços, soluções e produtos de dados.
Manter privacidade, segurança e veracidade dos dados.
Envolver-se em interação frequente com o cliente durante todo o ciclo de vida dos dados.
Escrever relatórios coerentes e fazer apresentações a especialistas e não especialistas.
Em relação às qualidades de data scientists, com base em anúncios de vagas de empregos de Google, Facebook, Linkedin, etc. (aquelas listas que aumentam a sensação de se estar buscando “unicórnios”, mas tudo bem):
Capacidade de pensar analiticamente, criativamente, criticamente e inquisitivamente.
Metodologias e conhecimento de sistemas complexos e abordagens para resolução de problemas de cima para baixo e de baixo para cima.
Mestre ou PhD em ciência da computação, estatística, matemática, análise, dados ciência, informática, engenharia, física, pesquisa operacional, reconhecimento de padrões, inteligência artificial, visualização, recuperação de informações ou campos relacionados — este ponto já tem sido questionado e revisto, por exemplo.
Conhecimento profundo de estatísticas comuns, mineração de dados e aprendizado de máquina.
Capacidade de implementar, manter e solucionar problemas de infraestrutura de big data, como computação em nuvem, infraestrutura de computação de alto desempenho, processamento distribuído paradigmas, processamento de fluxo e bancos de dados.
Conhecimento das interações homem-computador, visualização e representação e gestão do conhecimento.
Background em engenharia de software.
Experiência com grandes conjuntos de dados e tipos e fontes de dados mistos em um ambiente em rede e distribuído.
Experiência em extração e processamento de dados.
Interesse ativo e conhecimento em estudos multidisciplinares e transdisciplinares, e em métodos de área científicas, técnicas e sociais e da vida.
Experiência substancial com scripts orientados a análises de última geração, estruturas de dados, linguagens de programação e plataformas de desenvolvimento em Linux, nuvem ou ambiente distribuído.
Antecedentes teóricos e conhecimentos de domínio para a avaliação dos técnicos e méritos comerciais das descobertas analíticas.
Excelente comunicação escrita e verbal e habilidades organizacionais, capacidade de escrever e editar materiais analíticos e relatórios para diferentes públicos e capacidade de transformar conceitos e resultados analíticos em interpretações favoráveis aos negócios; capacidade de comunicar percepções acionáveis para pessoas não técnicas públicos e experiência em tomada de decisão baseada em dados.
(Se achar que é competência demais, nem queira olhar para a lista de ferramentas, linguagens de programação e softwares incluída no artigo, a qual certamente já está desatualizada e nunca será completa).
O interessante é que tudo isso não são criações do autor, mas das muitas referências que ele busca e que, não temos como negar, representam Data Science que conhecemos.
Note-se que partimos de algo que era sobre estatística, computação e machine learning (ou outros ingredientes óbvios que se quiser acrescentar) e caímos em conhecimento do domínio de negócio, habilidades de comunicação, “percepções acionáveis” e de “pensar analiticamente, criativamente, criticamente e inquisitivamente”, fora o que pode ter ficado de fora.
Empacotando
Poderíamos fazer uma arqueologia das explicações, conceituações e explicações sobre Data Science. Escreveríamos um livro com tudo o que foi encontrado e, provavelmente, ao fim, ainda não teríamos aquelas duas linhas lapidadas em pedra que definiriam bela e cabalmente o campo.
O exercício foi proposital, por isso o “tentando” lá do título. Uma compreensão verdadeiramente intuitiva, ampla, rica, não redutora, não simplificadora, não baseada em meia dúzia de lugares-comuns ou frases prontas, requer refletir sobre toda essa construção dinâmica, interdisciplinar e forjada na prática que a Ciência de Dados é.
Na teoria de sistemas complexos, na filosofia e em outros campos, há o conceito de emergência, que quer dizer que “o todo é mais do que a soma das partes”, como num ser vivo, em que a simples união e funcionamento de células, isto é, seus níveis físico e bioquímico, não explicam toda a complexidade de suas características e comportamentos.
Em certo sentido, talvez Data Science seja como uma emergência da interação das muitas partes distintas que vimos, cuja definição ou explicação sempre deixaram várias possibilidades de fora. Além disso, essas interações estão acontecendo em ritmo acelerado e imprevisível, o que dificulta mais um quadro consolidado.
Agora, com base em todo esse passeio conceitual, tente o exercício proposto lá no início. Escreva uma definição com suas próprias palavras. Se quiser ir além, dois dos artigos citados, Data Science: A Comprehensive Overview” e “50 Years of Data Science”, são ótimos pontos de partida.
Talvez você acabe nesse mesmo processo que elaboramos aqui, mas provavelmente, desenvolverá uma compreensão muito mais intuitiva e rica do que é Data Science para você mesmo, que qualquer resumo pronto jamais fornecerá.
Artigo escrito por Rogério Kreidlow, jornalista, que gosta de observar a tecnologia em relação a temas amplos, como política, economia, história e filosofia.